













Эта история началась пару месяцев назад, в первый день рождения моего сына. На мой телефон пришло СМС-сообщение с поздравлением и пожеланиями от неизвестного номера. Думаю, если бы это был мой день рождения мне бы хватило наглости отправить в ответ, не совсем культурное, по моему мнению, «Спасибо, а Вы кто?». Однако день рождения не мой, а узнать кто передаёт поздравления было интересно.
Первый успех
Было решено попробовать следующий вариант:
Мне повезло и в моём случае в списке контактов Viber рядом с вновь созданным контактом появилась миниатюра фотографии, по которой я, не открывая её целиком, распознал отправителя и удовлетворенный проведенным «расследованием» написал смс с благодарностью за поздравления.
Сразу же за секундным промежутком эйфории от удачного поиска в голове появилась идея перебором по списку номеров мобильных операторов составить базу [номер_телефона => фото]. А еще через секунду идея пропустить эти фотографии через систему распознавания лиц и связать с другими открытыми данными, например, фотографиями из социальных сетей.
Решение было найдено быстро: в сети есть программная реализация другого популярного сервиса — WhatsApp. Все вызовы идут через php. Есть готовый скрипт регистрации нового пользователя и собственно пример вызова getProfilePicture. Чтобы начать процесс нужен *nix сервер и нужно понять насколько можно обнаглеть с частотой и скоростью запросов. Для эксперимента был написан php код, который авторизуется в Whatsapp и в бесконечном цикле получает/не получает для номеров +7XXXXXXXXXX getProfilePicture и выдаёт на экран временную метку. Этот код при первом и последующих запусках доходил до 220-250 номеров и уходил в timeout — пробуем после каждого 200-го делать паузу sleep(5) — не помогает, всё равно timeout. Пробуем завершить процесс и сразу запустить заново — успех. Соответственно имеем дело либо с ограничением на сервере (необходимо после 200 запросов заново авторизоваться), либо с ошибкой в этой php реализации. Экспериментировать я не стал, а убил двух зайцев, переписав php скрипт, чтобы он обрабатывал только 200 номеров и добавив управляющий скрипт на Bash, который в цикле запускает php с параметром $startPhoneNumber и дожидается его завершения.
Таким образом получили работающую схему перебора со скоростью 5,7 номеров в секунду.
Для обработки всей московской ёмкости нам потребуется:
Многопоточность
Авторизация в WhatsApp идет через связку
username — номера телефона в формате +7XXXXXXXXXX
password — полученный через скрипт регистрации (для регистрации нужна работающая симкарта для получения кода подтверждения)
nickname — может быть любым
WhatsApp запрещает >1 авторизации на один username одномоментно. В связи с чем в официальном магазине было закуплено три SIM-карты оператора Мегафон по 200р. каждая. С одного и того же сервера на ОС Centos все три номера были зарегистрированы в WhatsApp и на всех трёх было запущено по скрипту с кусочком емкости «Билайн Бизнес». Соотношение количества номеров к сохраненным фотографиям держалось в районе 10 к 1-му; потом разница увеличилась благодаря «сотням» и «тысячам», которые видимо еще не распределены и для всего диапазона не дают ни одного изображения.
Блокировка
В лицензионном соглашении WhatsApp (с которым я соглашаюсь, когда прохожу регистрацию) сказано:
Отрывок из соглашения ENG
Отрывок из соглашения; примерный перевод
Все мои SIM-карты заблокировали на третий день без объяснения причин. По логам видно, что отключение произошло в 00:22 по Москве по всем картам одновременно (карты успели обработать каждая около 500 000 номеров). Что интересно сервера WhatsApp сначала стали очень долго отвечать на запросы, а потом вообще перестали авторизовывать. На попытку зарегистрировать номер заново сервер отвечает "Failed; Reason: Blocked;". При попытке зарегистрировать WhatsApp по-человечески с телефона выскакивает сообщение: «Извините, вы больше не можете пользоваться сервисом WhatsApp.»
Кроме того, что все три запущенных скрипта делали одно то же с одной и той же скоростью у них было много общего, чтобы заблокировать их одновременно, а именно: все логинились с одним и тем же nickname «V» и работали с одного и того же IP-адреса.
Усложняем схему

Считаем, что стали чуть-чуть (а именно на 600р. потраченные на те три SIM) умней. На этот раз покупаем 10 сим карт в «неофициальном магазине» у метро по 100р. за штуку. Усложняем скрипт, создаём массив симкарт и даём каждой свой nickname согласно списку актёров одного замечательного фильма:
Объявление массива
Заставляем каждую сим карту выходить через отдельный IP адрес
Делим емкость на кусочки меньше 2 000 номеров. Также добавляем в Bash и php скрипты Push-уведомления через Pushover («7XXXXX start», «7XXXXX finish», «Houston we have a problem»)
Последнее отправляем при нестандартных ответах сервера WhatsApp, либо при очень долгом (>5 секунд) отсутствии ответа.
Забегая вперёд хочу сказать, что WhatsApp хитрее меня и все эти симкарты тоже были заблокированы через некоторое время и тоже почти одновременно. В любом случае 8 000 000 телефонных номеров скрипты всё-таки успешно проработали и у нас на руках 411 279 фотографий. Соотношение 20 к 1. Что уже вполне неплохо.

Выборка из результатов обработки по г. Москва
Ненецкий автономный округ
Долгое время не было возможности активировать оставшиеся сим-карты и запустить скрипты. Наконец свободная минута появилась, а вместе с ней силы признать, что начинать перебор с Москвы (население
ВКонтакте
Задача: получить все фотографии пользователей VK, у которых указан интересующий нас город.
Немалое количество времени ушло, чтобы разобраться с VK API. И оказалось, что запрос getuser выполнить можно без проблем, не имея access-token. А вот запрос search (чтобы взять только людей из конкретного города) сработает только с токеном, причём полученным на пользователя, а не на standalone приложение. В этом нам поможет статья
Пробуем пойти через get_users перебором: перебираем всех пользователей вконтакте от $id = 1 до N следующим запросом:
response=$(curl --silent "https:// api.vk.com /method/users.get?user_id=$id&fields=photo_max_orig,country,city")
В сети вконтакте на момент написания этой статьи было N =
Итого около 3472 дней в одном потоке, при условии, что VK не будет блокировать наши IP-адреса. Вариант отбрасываем.
Возвращаемся к users.search с ограничением на количество в выдаче, но не на «качество» запроса. Поясняю. В запросе можно бесконечно уточнять параметры: например, взять только женщин или мужчин, уменьшив выдачу в два раза, или взять только тех, у кого есть фото, и что самое удобное — взять только людей конкретного возраста, естественно в цикле от $age = 14 до 80. Итого 66 прогонов по 1000, с замечанием, что, если для некоторых возрастов мы перевалим за 1000 — такие запросы мы повторим с дополнительным разделением по полу.
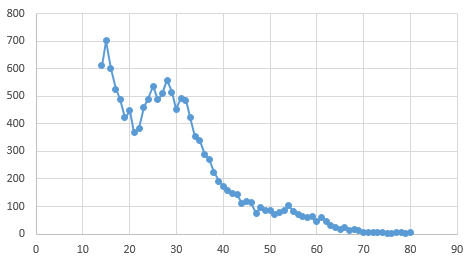
Распределение пользователей VK из г. Нарьян-Мар по возрасту
Скрипт постепенного скачивания из VK
На 19 годах VK что-то заподозрили, и стали очень медленно отвечать на запросы. Через полтора часа было скачано 13 967 изображений. У остальных 1 700 человек возраст видимо не был указан вообще. Еще 400 скачанных изображений оказались, по каким-то причинам битыми, либо очень маленькими (<10 кб).
Распознавание и сравнение лиц
Как мы уже выяснили среди полученных изображений множество котов и автомобилей, поэтому для начала хочется их отфильтровать. Поможет нам с этим OpenCV (Open Source Computer Vision Library, библиотека компьютерного зрения с открытым исходным кодом).
Существует множество реализаций, на различных языках программирования, основанных на этой библиотеке. Например, facedetect, которая определяет координаты по которым находится лицо на фото. Она же вместе с ImageMagick вырежет по координатам распознанное лицо в отдельный файл.
По распознаванию лиц на фото, есть интересная реализация от компании Betaface. У них платное API для большого количества изображений, но есть отличная

Мы же возьмем готовые скрипты на python от английского разработчика Terence Eden. Он написал их в рамках очень
Корректируем скрипт Тэренса — выключаем скачивание из Британской галереи и удаляем обработку по папкам.
Скрипт на python
Итог обработки:
13 500 изображений из VK => 6 427 / 5 446 лиц. (с учетом / без учёта случаев с несколькими лицами на одном фото)
2 208 из WhatsApp => 963 / 876 лиц
Проглядывается интересная закономерность — каждый второй пользователь не ставит фото на профиль.
Следом за распознанием идёт создание модели eigenfaces.xml. Скриптом предусмотрено по папке исходных фотографий сформировать XML файл, по которому в будущем будет производиться поиск. Поэтому по одному комплекту готовим такой файл, а из второго потом берём по одному элементу и ищем соответствие. Техника решила за меня какой из комплектов брать за основной: 6 400 фотографий из VK скрипт обработать не смог с ошибкой по памяти "Couldn't allocate over 4GB". Время — 11 ночи — разбираться не охота — пропускаем через скрипт 963 фото из WhatsApp и через 20 минут имеем eigenfaces.xml размером 1.6 ГБ. Можно представить какого бы размера он был в случае с VK. Позже оказалось, переделывая скрипт под себя, я случайно удалил строку идентификации в модели, вместо неё все элементы имели идентификатор «0». Смешно бы было прождать несколько дней выполнения скрипта и только потом это обнаружить. Исправляем ошибку и ждём еще 20 минут.
Затем для каждого файла из VK запускаем скрипт проверки.
find detectedVK/ -name *.jpg -exec ./myscript.sh {} \;
#myscript.sh
python recognise.py detectedWH $1 100000 >> result
`100000` здесь — точность совпадения, при 100 — идеальное совпадение.
На одно сравнение имеем 40 секунд. 6 400 * 40 ~ 3 дня на одном процессоре. Оставляем на ночь; идем спать — завтра понедельник.
Сразу скажу, что у меня были мысли, что для такой маленькой выборки совпадений будет ноль. Пока работали скрипты я периодически смотрел на совпадения. С указанной мною точностью результатов было много, но при ближайшем рассмотрении даже на совпадениях порядка `3500` было множество результатов мальчик-девочка. При том создавалось ощущение, что эти двое родственники. Результат интересный, но это не совсем то, что мы искали.
Первое попадание случилось к концу первой тысячи аккаунтов. Девушка Яна из города Нарьян-Мар поставила одинаковую фотографию и в WhatsApp и в VK. Несмотря на то, что фото одинаковые (отличается только разрешение) точность совпадения ~3 000. Для всех результатов с точностью <6000 с помощью convert объединяем совпавшие изображения, чтобы зрительно окончательно принять решение
...
if [ "$precise" -lt 6000 ]
then
echo $precise $whIMG $vkIMG
convert detectedWH.bak/$whIMG detectedVK.bak/$vkIMG -append convertResults/${precise}_$whIMG$vkIMG
fi
...

Итого к окончанию вторых суток успешно распознаны и привязаны к номеру телефона 25 аккаунтов VK.
Это 2% от числа найденных лиц WhatsApp, либо 1% от всех изображений.

Результаты анализа по г.Нарьян-Мар
Я верю, что это отличный результат, и вот почему:
Тут сложно говорить о конкретных цифрах, но можно точно сказать, что процент успешных попаданий значительно увеличится, если соблюсти все пункты. Процессорные мощности для этого конечно тоже надо увеличить в несколько раз.
Заключение
К чему это всё. Полезного для общества практического применения полученных данных я пока не придумал. Получилось небольшое исследование ради исследования.
Библиотека OpenCV отличный инструмент, используя который на полученных данных, можно провести еще ряд интересных экспериментов.
В награду дочитавшим до конца, такой, например, весёлый вариант: Собрать модель eigenfaces.xml по фотографиям известных актрис, российских и зарубежных, и провести перебор на соответствие по полученной из WhatsApp базе москвичей (у нас их на данный момент ~400 000). Не беря во внимание моральную составляющую (а именно, вопрос: культурно ли звонить незнакомым людям), набираем номер и приглашаем в кино. Прикольно ведь пойти в кино с девушкой, которая с точностью 3000 к 100 похожа на главную героиню.

Еще в качестве вывода можно было бы сказать: «Не забывайте ставить галочки в настройках приватности». Но я не большой сторонник параноидальных настроений (" Они знают где я", «Интернет-провайдер знает обо мне всё», «Большой брат следит за нами» и пр.). Меня, например, веселит, когда моя жена выключает сбор анонимных геоданных на телефоне, со словами, что её «найдут» (кто, а главное зачем она пока не придумала).
Не знаю будет ли меня когда-нибудь кто-нибудь искать — я в своей жизни вроде бы ничего не нарушал (кроме лицензионного соглашения WhatsApp).
С хабра
Первый успех
Было решено попробовать следующий вариант:
- Добавить неизвестный номер в адресную книгу телефона;
- Зайти по очереди в приложения, привязанные к номеру (Viber, WhatsApp);
- Открыть новый чат с вновь созданным контактом и по фотографии определить отправителя.
Мне повезло и в моём случае в списке контактов Viber рядом с вновь созданным контактом появилась миниатюра фотографии, по которой я, не открывая её целиком, распознал отправителя и удовлетворенный проведенным «расследованием» написал смс с благодарностью за поздравления.
Сразу же за секундным промежутком эйфории от удачного поиска в голове появилась идея перебором по списку номеров мобильных операторов составить базу [номер_телефона => фото]. А еще через секунду идея пропустить эти фотографии через систему распознавания лиц и связать с другими открытыми данными, например, фотографиями из социальных сетей.
Для просмотра ссылки необходимо нажать
Вход или Регистрация
. Так что идея получить базу таким вот «решением в лоб» отпадает. Тем более, что даже если Viber возьмет хотя бы первую пачку в 25 000 номеров, все равно в каждый профиль нужно зайти, а потом еще связать получившийся файл [Хэш].jpg с конкретным номером (что, наверное, можно отследить по дате создания файла, но это всё равно очень трудоёмко и долго).Решение было найдено быстро: в сети есть программная реализация другого популярного сервиса — WhatsApp. Все вызовы идут через php. Есть готовый скрипт регистрации нового пользователя и собственно пример вызова getProfilePicture. Чтобы начать процесс нужен *nix сервер и нужно понять насколько можно обнаглеть с частотой и скоростью запросов. Для эксперимента был написан php код, который авторизуется в Whatsapp и в бесконечном цикле получает/не получает для номеров +7XXXXXXXXXX getProfilePicture и выдаёт на экран временную метку. Этот код при первом и последующих запусках доходил до 220-250 номеров и уходил в timeout — пробуем после каждого 200-го делать паузу sleep(5) — не помогает, всё равно timeout. Пробуем завершить процесс и сразу запустить заново — успех. Соответственно имеем дело либо с ограничением на сервере (необходимо после 200 запросов заново авторизоваться), либо с ошибкой в этой php реализации. Экспериментировать я не стал, а убил двух зайцев, переписав php скрипт, чтобы он обрабатывал только 200 номеров и добавив управляющий скрипт на Bash, который в цикле запускает php с параметром $startPhoneNumber и дожидается его завершения.
Таким образом получили работающую схему перебора со скоростью 5,7 номеров в секунду.
Для обработки всей московской ёмкости нам потребуется:
Для просмотра ссылки необходимо нажать
Вход или Регистрация
(номеров) / 5.7 (номеров в секунду) / 60 (секунд) / 60 (минут) / 24 (часа) ~ 190 дней.Многопоточность
Авторизация в WhatsApp идет через связку
username — номера телефона в формате +7XXXXXXXXXX
password — полученный через скрипт регистрации (для регистрации нужна работающая симкарта для получения кода подтверждения)
nickname — может быть любым
WhatsApp запрещает >1 авторизации на один username одномоментно. В связи с чем в официальном магазине было закуплено три SIM-карты оператора Мегафон по 200р. каждая. С одного и того же сервера на ОС Centos все три номера были зарегистрированы в WhatsApp и на всех трёх было запущено по скрипту с кусочком емкости «Билайн Бизнес». Соотношение количества номеров к сохраненным фотографиям держалось в районе 10 к 1-му; потом разница увеличилась благодаря «сотням» и «тысячам», которые видимо еще не распределены и для всего диапазона не дают ни одного изображения.
Блокировка
В лицензионном соглашении WhatsApp (с которым я соглашаюсь, когда прохожу регистрацию) сказано:
Отрывок из соглашения ENG
Отрывок из соглашения; примерный перевод
Все мои SIM-карты заблокировали на третий день без объяснения причин. По логам видно, что отключение произошло в 00:22 по Москве по всем картам одновременно (карты успели обработать каждая около 500 000 номеров). Что интересно сервера WhatsApp сначала стали очень долго отвечать на запросы, а потом вообще перестали авторизовывать. На попытку зарегистрировать номер заново сервер отвечает "Failed; Reason: Blocked;". При попытке зарегистрировать WhatsApp по-человечески с телефона выскакивает сообщение: «Извините, вы больше не можете пользоваться сервисом WhatsApp.»
Кроме того, что все три запущенных скрипта делали одно то же с одной и той же скоростью у них было много общего, чтобы заблокировать их одновременно, а именно: все логинились с одним и тем же nickname «V» и работали с одного и того же IP-адреса.
Усложняем схему
Считаем, что стали чуть-чуть (а именно на 600р. потраченные на те три SIM) умней. На этот раз покупаем 10 сим карт в «неофициальном магазине» у метро по 100р. за штуку. Усложняем скрипт, создаём массив симкарт и даём каждой свой nickname согласно списку актёров одного замечательного фильма:
Объявление массива
Заставляем каждую сим карту выходить через отдельный IP адрес
Делим емкость на кусочки меньше 2 000 номеров. Также добавляем в Bash и php скрипты Push-уведомления через Pushover («7XXXXX start», «7XXXXX finish», «Houston we have a problem»)
Последнее отправляем при нестандартных ответах сервера WhatsApp, либо при очень долгом (>5 секунд) отсутствии ответа.
Забегая вперёд хочу сказать, что WhatsApp хитрее меня и все эти симкарты тоже были заблокированы через некоторое время и тоже почти одновременно. В любом случае 8 000 000 телефонных номеров скрипты всё-таки успешно проработали и у нас на руках 411 279 фотографий. Соотношение 20 к 1. Что уже вполне неплохо.
Выборка из результатов обработки по г. Москва
Ненецкий автономный округ
Долгое время не было возможности активировать оставшиеся сим-карты и запустить скрипты. Наконец свободная минута появилась, а вместе с ней силы признать, что начинать перебор с Москвы (население
Для просмотра ссылки необходимо нажать
Вход или Регистрация
человек) — это лихо. Поэтому прячем поглубже свой юношеский максимализм и берём менее населенный субъект, например, Ненецкий автономный округ. Почему бы и нет. Запускаем скрипт — и через 12 часов перебор всех емкостей Ненецкого округа завершен. Для 169 995 номеров было найдено всего 2 208 фотографий в WhatsApp. Переходим к следующему этапу.ВКонтакте
Задача: получить все фотографии пользователей VK, у которых указан интересующий нас город.
Немалое количество времени ушло, чтобы разобраться с VK API. И оказалось, что запрос getuser выполнить можно без проблем, не имея access-token. А вот запрос search (чтобы взять только людей из конкретного города) сработает только с токеном, причём полученным на пользователя, а не на standalone приложение. В этом нам поможет статья
Для просмотра ссылки необходимо нажать
Вход или Регистрация
. Но даже когда мы получили этот токен — мы утыкаемся в ограничение — получить можно только 1000 пользователей (не 1000 за один запрос, а 1000 всего), при том, что, например, город Нарьян-Мар (Ненецкий АО) указан у 15 660 человек.Пробуем пойти через get_users перебором: перебираем всех пользователей вконтакте от $id = 1 до N следующим запросом:
response=$(curl --silent "https:// api.vk.com /method/users.get?user_id=$id&fields=photo_max_orig,country,city")
В сети вконтакте на момент написания этой статьи было N =
Для просмотра ссылки необходимо нажать
Вход или Регистрация
пользователей. На один такой запрос без скачивания фото уходила 1 секунда.
Для просмотра ссылки необходимо нажать
Вход или Регистрация
(пользователей) / 1 (в секунду) / 60 (секунд) / 60 (минут) / 24 (часа) ~ 3472 дней.Итого около 3472 дней в одном потоке, при условии, что VK не будет блокировать наши IP-адреса. Вариант отбрасываем.
Возвращаемся к users.search с ограничением на количество в выдаче, но не на «качество» запроса. Поясняю. В запросе можно бесконечно уточнять параметры: например, взять только женщин или мужчин, уменьшив выдачу в два раза, или взять только тех, у кого есть фото, и что самое удобное — взять только людей конкретного возраста, естественно в цикле от $age = 14 до 80. Итого 66 прогонов по 1000, с замечанием, что, если для некоторых возрастов мы перевалим за 1000 — такие запросы мы повторим с дополнительным разделением по полу.
Распределение пользователей VK из г. Нарьян-Мар по возрасту
Скрипт постепенного скачивания из VK
На 19 годах VK что-то заподозрили, и стали очень медленно отвечать на запросы. Через полтора часа было скачано 13 967 изображений. У остальных 1 700 человек возраст видимо не был указан вообще. Еще 400 скачанных изображений оказались, по каким-то причинам битыми, либо очень маленькими (<10 кб).
Распознавание и сравнение лиц
Как мы уже выяснили среди полученных изображений множество котов и автомобилей, поэтому для начала хочется их отфильтровать. Поможет нам с этим OpenCV (Open Source Computer Vision Library, библиотека компьютерного зрения с открытым исходным кодом).
Существует множество реализаций, на различных языках программирования, основанных на этой библиотеке. Например, facedetect, которая определяет координаты по которым находится лицо на фото. Она же вместе с ImageMagick вырежет по координатам распознанное лицо в отдельный файл.
По распознаванию лиц на фото, есть интересная реализация от компании Betaface. У них платное API для большого количества изображений, но есть отличная
Для просмотра ссылки необходимо нажать
Вход или Регистрация
, которая распознает всех присутствующих на загруженном фото и кроме прочего определяет пол, наличие усов, очков, улыбки и (женщинам это не понравится) показывает предположительный возраст (мне даёт 27, плюшевому кролику на холодильнике — 42).
Мы же возьмем готовые скрипты на python от английского разработчика Terence Eden. Он написал их в рамках очень
Для просмотра ссылки необходимо нажать
Вход или Регистрация
. В его задаче стояло: скачать открытую коллекцию картин Лондонского музея «Тейт Британия», и распознать на ней изображения людей. Затем с помощью получившейся базы лиц и своей фотографии можно найти картину, на которой изображен человек максимально похожий на тебя. Web API он, к сожалению, не даёт, но все исходники есть на github.Корректируем скрипт Тэренса — выключаем скачивание из Британской галереи и удаляем обработку по папкам.
Скрипт на python
Итог обработки:
13 500 изображений из VK => 6 427 / 5 446 лиц. (с учетом / без учёта случаев с несколькими лицами на одном фото)
2 208 из WhatsApp => 963 / 876 лиц
Проглядывается интересная закономерность — каждый второй пользователь не ставит фото на профиль.
Следом за распознанием идёт создание модели eigenfaces.xml. Скриптом предусмотрено по папке исходных фотографий сформировать XML файл, по которому в будущем будет производиться поиск. Поэтому по одному комплекту готовим такой файл, а из второго потом берём по одному элементу и ищем соответствие. Техника решила за меня какой из комплектов брать за основной: 6 400 фотографий из VK скрипт обработать не смог с ошибкой по памяти "Couldn't allocate over 4GB". Время — 11 ночи — разбираться не охота — пропускаем через скрипт 963 фото из WhatsApp и через 20 минут имеем eigenfaces.xml размером 1.6 ГБ. Можно представить какого бы размера он был в случае с VK. Позже оказалось, переделывая скрипт под себя, я случайно удалил строку идентификации в модели, вместо неё все элементы имели идентификатор «0». Смешно бы было прождать несколько дней выполнения скрипта и только потом это обнаружить. Исправляем ошибку и ждём еще 20 минут.
Затем для каждого файла из VK запускаем скрипт проверки.
find detectedVK/ -name *.jpg -exec ./myscript.sh {} \;
#myscript.sh
python recognise.py detectedWH $1 100000 >> result
`100000` здесь — точность совпадения, при 100 — идеальное совпадение.
На одно сравнение имеем 40 секунд. 6 400 * 40 ~ 3 дня на одном процессоре. Оставляем на ночь; идем спать — завтра понедельник.
Сразу скажу, что у меня были мысли, что для такой маленькой выборки совпадений будет ноль. Пока работали скрипты я периодически смотрел на совпадения. С указанной мною точностью результатов было много, но при ближайшем рассмотрении даже на совпадениях порядка `3500` было множество результатов мальчик-девочка. При том создавалось ощущение, что эти двое родственники. Результат интересный, но это не совсем то, что мы искали.
Первое попадание случилось к концу первой тысячи аккаунтов. Девушка Яна из города Нарьян-Мар поставила одинаковую фотографию и в WhatsApp и в VK. Несмотря на то, что фото одинаковые (отличается только разрешение) точность совпадения ~3 000. Для всех результатов с точностью <6000 с помощью convert объединяем совпавшие изображения, чтобы зрительно окончательно принять решение
...
if [ "$precise" -lt 6000 ]
then
echo $precise $whIMG $vkIMG
convert detectedWH.bak/$whIMG detectedVK.bak/$vkIMG -append convertResults/${precise}_$whIMG$vkIMG
fi
...
Итого к окончанию вторых суток успешно распознаны и привязаны к номеру телефона 25 аккаунтов VK.
Это 2% от числа найденных лиц WhatsApp, либо 1% от всех изображений.
Результаты анализа по г.Нарьян-Мар
Я верю, что это отличный результат, и вот почему:
- У нас маленькие выборки, с большой разницей между ними (16 600 VK против 2 000 WhatsApp);
- Для поиска совпадений мы использовали только алгоритм Eigenfaces, а можно добавить, например, Fisherfaces;
- Можно увеличить шансы на распознание добавив по аналогии перебор через Viber;
- Из VK можно брать не только последнее фото профиля, но и несколько предыдущих;
- Наконец, к списку социальных сетей можно добавить Facebook, Одноклассники и пр.
Тут сложно говорить о конкретных цифрах, но можно точно сказать, что процент успешных попаданий значительно увеличится, если соблюсти все пункты. Процессорные мощности для этого конечно тоже надо увеличить в несколько раз.
Заключение
К чему это всё. Полезного для общества практического применения полученных данных я пока не придумал. Получилось небольшое исследование ради исследования.
Библиотека OpenCV отличный инструмент, используя который на полученных данных, можно провести еще ряд интересных экспериментов.
В награду дочитавшим до конца, такой, например, весёлый вариант: Собрать модель eigenfaces.xml по фотографиям известных актрис, российских и зарубежных, и провести перебор на соответствие по полученной из WhatsApp базе москвичей (у нас их на данный момент ~400 000). Не беря во внимание моральную составляющую (а именно, вопрос: культурно ли звонить незнакомым людям), набираем номер и приглашаем в кино. Прикольно ведь пойти в кино с девушкой, которая с точностью 3000 к 100 похожа на главную героиню.
Еще в качестве вывода можно было бы сказать: «Не забывайте ставить галочки в настройках приватности». Но я не большой сторонник параноидальных настроений (" Они знают где я", «Интернет-провайдер знает обо мне всё», «Большой брат следит за нами» и пр.). Меня, например, веселит, когда моя жена выключает сбор анонимных геоданных на телефоне, со словами, что её «найдут» (кто, а главное зачем она пока не придумала).
Не знаю будет ли меня когда-нибудь кто-нибудь искать — я в своей жизни вроде бы ничего не нарушал (кроме лицензионного соглашения WhatsApp).
С хабра